淺談memory cache
因為最近有朋友問我關於cache的問題,覺得這部份應該很多人一知半解,決定整理出一篇易懂易了解的cache解釋。
當初記憶體為什麼要像現在設計成階層式的架構?很簡單,因為我們發現我們寫的程式在存取記憶體的過程中,有兩大現象:
- 剛剛用過的記憶體很容易再被使用(例如,for迴圈)
- 如果一個記憶體剛剛使用過,他附近的記憶體位址也很可能被使用到(例如,陣列存取)
這就產生了設計記憶體架構的兩大原則,Temporal Locality和Spatial Locality。另外還有記憶體本身的速度、成本的考量,越快的記憶體越貴,我們決定設計出階層式的記憶體架構。
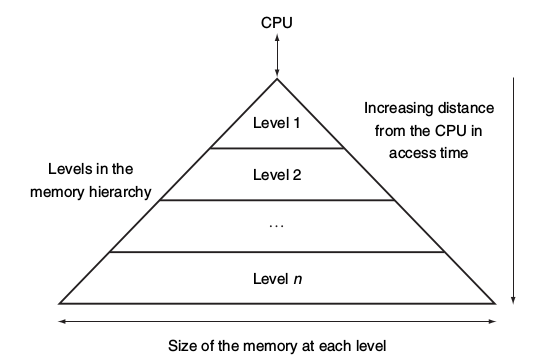
越上層的記憶體越貴,速度越快,容量越小。越下層記憶體越便宜,速度慢,但容量越大�。資料只會在相鄰兩層間移動。
我們把資料一次從記憶體下層轉移到記體上層的單位定作block。如果處理器要求讀取某個block的資料,剛好在上層的記憶體內,那就稱為hit。如果不在上層,那就稱為miss。hit rate就是你成功在上層記憶體就找到你要的資料的次數比例。相反的就是miss rate。hit rate + miss rate = 1。現今電腦的hit rate都已經達到驚人的95%以上。
另一個對電腦效能來說影響重大的因素就是hit time和miss penalty
- hit time
- 判斷記憶體是否hit + 把上層資料搬到處理器的時間
- miss penalty
- 把下層記憶體的資料搬到上層 + 上層記憶體資料搬到處理器的時間
cache設計的概念
cache在設計的時候,就要先回答一個重要的問題:
處理器怎麼知道data是否在cache中,並且正確的從cache抓出想要的資料?
direct map
設計cache的配置有很多種不同的方式,我們先學習最簡單的方式direct-map(也被稱為One-way set associative)

direct-map顧名思義,就是直接根據記憶體位置,把所有區塊平均分配給cache。看圖應該就能理解配置的方法,cache內有000~111 8個block,memory內有00000~11111 32個block,memory內的block index結尾只要等於cache index,就代表該block可以被放到該cache的該位置。也就是灰色的部份(00001, 01001, 10001, 11001)都可以被放到cache 001 block內。
tag
但這樣設計的問題就是,我要怎麼知道我想要的記憶體資料剛好在cache內? 答案是多設計一個tag欄位,讓tag紀錄該cache所紀錄的資料在原本記憶體中的位置。tag不需要完整紀錄該cache存放內容的記憶體位址,他只要紀錄前面幾個bit就好了。以上圖為例,我想知道cache index 001到底是存放(00001, 01001, 10001, 11001),只要額外紀錄前兩個bit就好。
valid bit
另外cache還需要valid bit,來紀錄該cache是否包含有效資訊。例如處理器剛啟動時,cache內並沒有任何東西,此時cache內容全是無效的,要經過一段時間才會塞滿內容。
實際範例
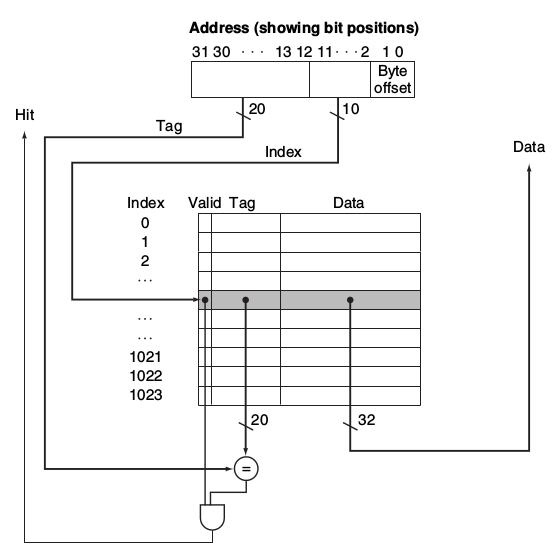
直接看圖了解最快,這是一個32bit的address,direct map到1024個block的cache。word是處理器指令集存取memory的單位。在此架構中一個word是4個bytes,因此我們需要兩個bit來決定到底是該word的哪一個bytes。該圖cache內1個block的大小是1個word,總共有1024個block,所以我們用10 bits來表示該cache index,剩下20個bits就作為tag。因此存取該cache意思就是取出2~11 bit找到cache index,並比較tag(12~31 bit)決定是否hit�,如果hit到,就讀出資料。
實際上,一個block可能存放不只一個word。假設一個block存放2^m個word(也就是一個block 2^(m+2) bytes),所以一個cache內有m個bit會被用來找是該block的哪個word,有2個bit會被用來找該word的哪個byte。
因此一個32bit的記憶體位址大概會分成 [tag][cache index][word index][byte index]。 一個cache的實際佔用空間是2^n*(valid field size + tag size + block size)
但傳統上,我們會只計算cache的的資料空間作為cache size,也就是我們會把上圖稱為4KB的cache(1024個block,一個block內有4byte的資料)
舉例
使用32bit address,一個可以放16KB data的cache,每個block有4個word,實際上會需要多大的cache? 16 KB = 2^14 bytes = 2^12 word,一個block 4個word,所以總共有2^10 block。 每個block有4個word,也就是128bit,tag的長度是32 - 10 - 2 - 2 = 18 bit(32扣除block index, word index, byte index),外加一個valid bit,因此總共是 2^10 * (128 + 18 + 1) = 2^10 * 147 = 147 Kbit
block size與miss rate的關係
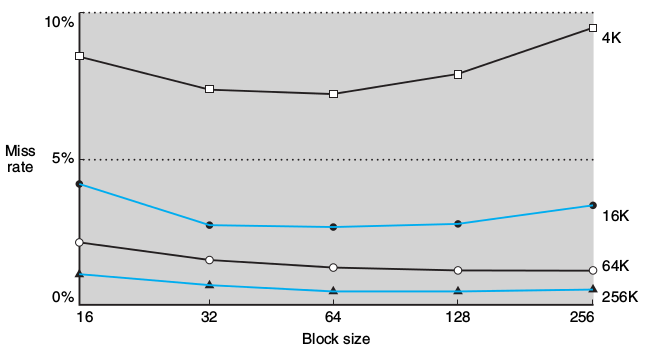
在同樣的cache size下,如果提昇block size,會降低miss rate,因為你提昇了spatial locality。但是如果你無限制的提高block size,反而會導致cache內的總block數太少。另一個提高block size會造成的問題是miss penalty變大,因為一旦miss,你須要轉移更多的記憶體內容。
記憶體的組織(Memory Organization)
在以下的假設下,我們比較一下不同記憶體配置方式的效能
- 以word為單位傳輸
- cache block size為8 words。
- 1 clock cycle 送出想要讀取的記憶體位址
- 10 clock cycles 存取記憶體內容
- 1 clock cycle 讓bus傳回資料
One-word-wide memory organization
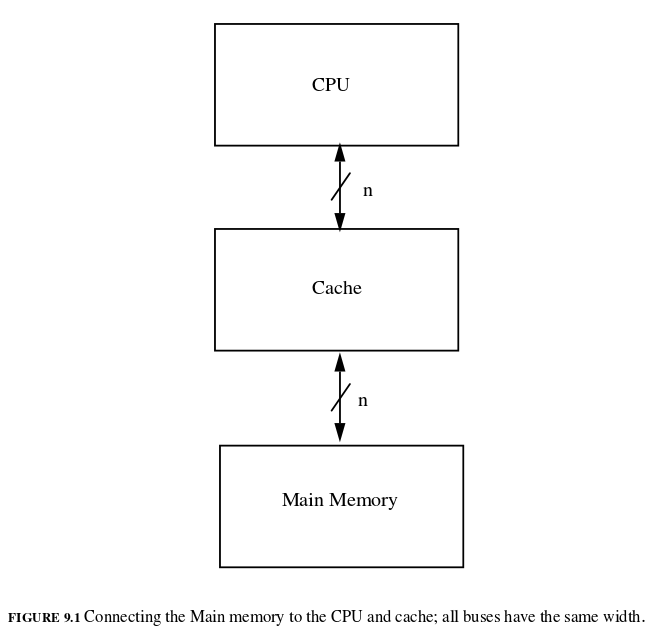
一次只能傳一個word的記憶體架構。
計算miss penalty 和 memory bandwidth
在此架構下發生miss,則必須把memory的內容搬到cache裡,每次搬運一個word,需要1個cycle傳送想讀的記憶體位址,10個cycle去讀取記憶體,然後1個cycle把記憶體資料放進cache內。所以8個word總共需要:
miss penalty = 8 * (1 + 10 + 1) = 96
memory bandwidth = bytes_transferred / clock_cyle 32bytes(8 words)/96 clock = 0.33 bytes/clock cycle
要如何提昇記憶體bandwidth呢?你可以選擇每次傳更多bytes,或每次花更少的clock傳同樣數量的bytes。這兩種思維導致了以下兩種設計架構
Wider Main Memory
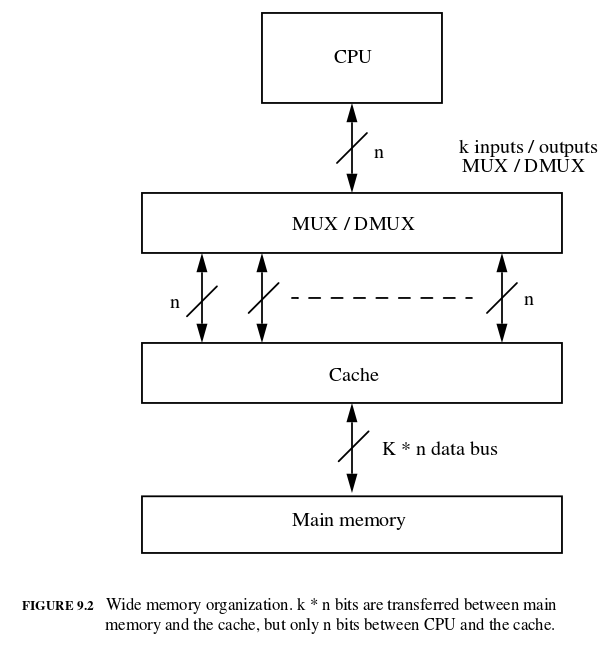
特色是cache和main memory之間的bus比CPU和cache間的bus還要寬。CPU和cache一次只會傳1個word,但cache和memory會一次傳k個word。在這種情況下,發生miss時,記憶體可以一次搬運大量的資料到cache內。
計算miss penalty 和 memory bandwidth
需要1個cycle傳送要取得的記憶體位址,10個cycle去讀取記憶體(此時一次取得8個word),然後1個cycle把記憶體資料放進cache內。 miss penalty = 1 + 10 + 1 = 12
memory bandwidth = bytes_transferred / clock_cyle 32 / 12 = 2.67 bytes/clock cycle
老樣子,每種架構都有自己的代價,這樣的架構需要更多線,所以成本一定更高。另外因為CPU一次只能讀取一個word,但是cache內每個block有8個word,所以必須要有一個mux去選擇該個block內的某個word。
實際上cache設計會長的像這樣,看圖應該就能理解了:
Interleaved Memory
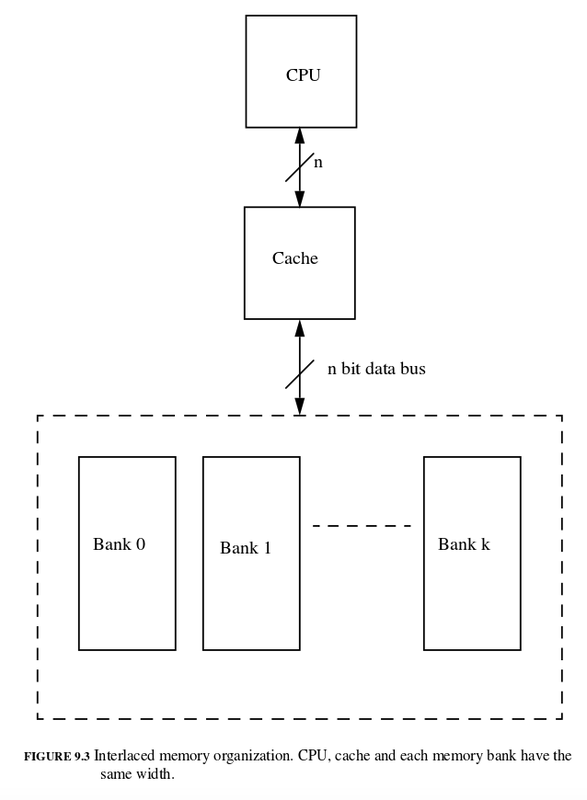 Interleaved的意思是交錯的,在這種架構下記憶體被分割成許多個bank,每個bank的頻寬是one-word。這樣設計的好處可以一次讀取多個word,再一個一個傳送到cache內。
Interleaved的意思是交錯的,在這種架構下記憶體被分割成許多個bank,每個bank的頻寬是one-word。這樣設計的好處可以一次讀取多個word,再一個一個傳送到cache內。
計算miss penalty 和 memory bandwidth
該記憶體有4個bank,1個cycle送出要讀取記憶體位置,10個cycle讓記憶體讀取資料,4個cycle送出來自4個bank的4個word,總共要讀出8個word。 miss penalty = 2 * (1 + 10 + 4 * 1) = 30 clock cycle memory bandwidth = bytes_transferred / clock_cyle 32 / 30 = 1.1 bytes/clock cycle
這樣設計的好處是折衷,他不像one-word-width memory這麼慢,但是又不像wider memory需要更大的bus。影響效能的關鍵在於記憶體位址是如何分配到各個bank內,一般來說連續的記憶體會被分到不同的bank內,這樣一次可以從不同的bank抓出連續的記憶體資料。
談cache block的配置
剛剛我們談的是在同樣的cache下,不同的main memory架構會如何影響cache的效能,現在我們換個問題:改變cache的架構呢? 我們一開始採用的是最簡單的Direct-map配置,也就是每個main memory上的記憶體只會出現在特定的cache位置內。
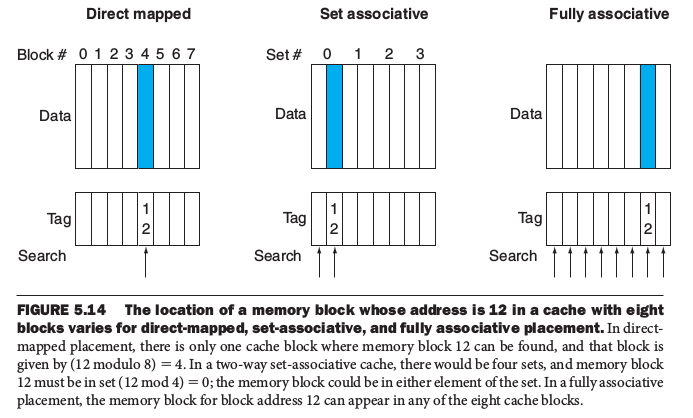
其他還有set associaltive的方式,也就是把cache分成多個set,CPU必須檢查指定set內的每個block是否有可用的cache。最極端的情況下就是Fully Associative,也就是CPU要檢查cache內所有的block。
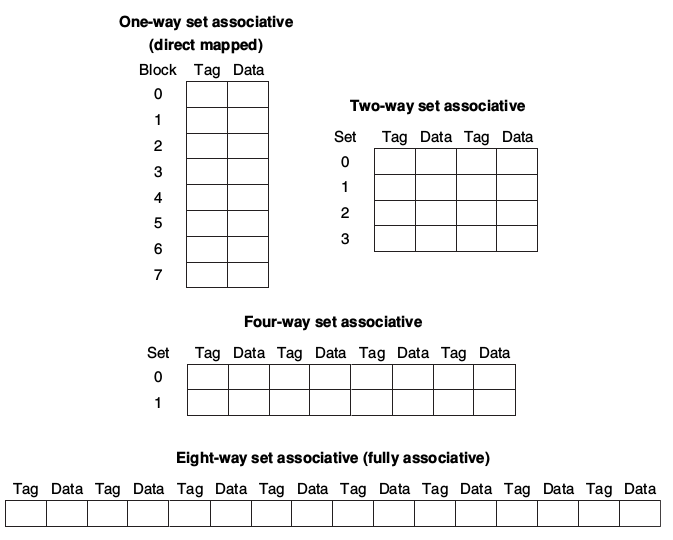
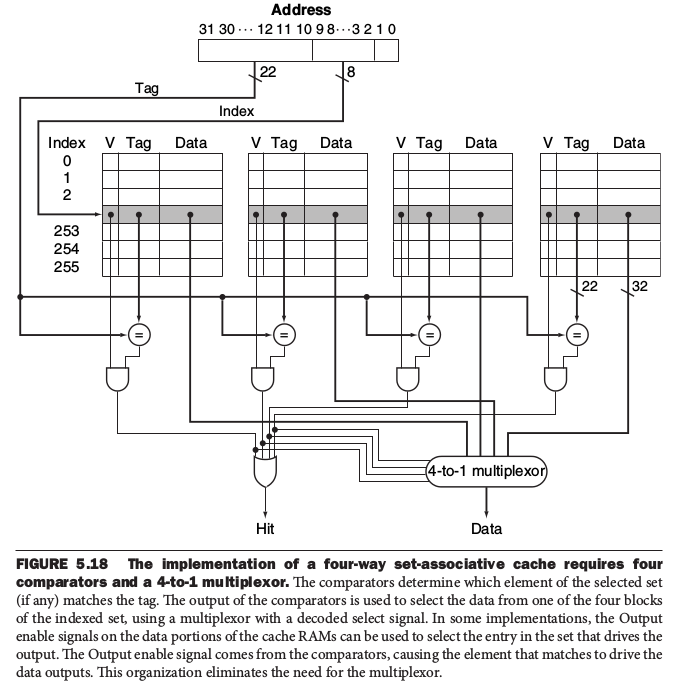
實作多個four-way set的方式
以上就是cache的簡易介紹,詳情請翻閱你手邊的算盤書。
資料來源: